Architecture > API Architecture
File Upload
Learn about the necessary cloud infrastructure resources on which the API project application relies on to upload files.
- how file uploads are handled by the deployed cloud infrastructure and application code
Diagram
For brevity, the diagram doesn’t include network-level cloud infrastructure resources, like region, VPC, availability zones, and so on. Check out the Deployment Modes section if you’re interested in that aspect of the deployed cloud infrastructure.
Note that the stateful resources like Amazon S3, Amazon Cognito, Amazon DynamoDB and Amazon OpenSearch are deployed as part of the Core project application. These are still included in the diagram, just so it’s more clear to the reader.
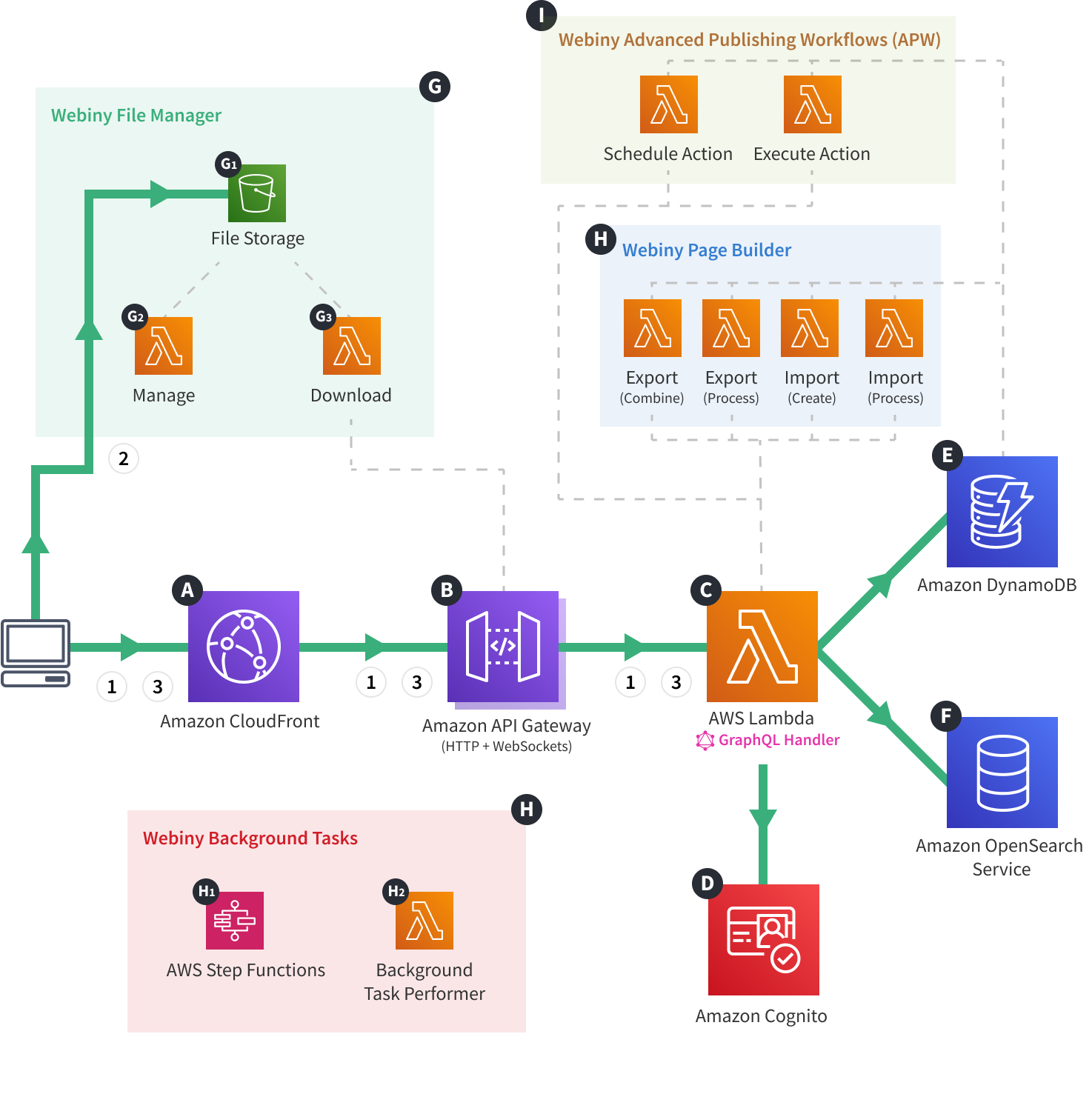 Webiny Cloud Infrastructure - API - File Upload
Webiny Cloud Infrastructure - API - File UploadDescription
The diagram shows what happens every time a client tries to upload a binary file.
To provide file upload functionality, the File Manager application relies on a method called pre-signed POST payload. Once certain conditions are met, the method enables uploading files directly to an S3 bucket, which is significantly more efficient than having the file travel through multiple cloud infrastructure resources.
If you want to learn more, feel free to check out a blog post we wrote on this exact subject and which explains the process in detail.
we wrote on this exact subject and which explains the process in detail.
The flow consists of the following three steps:
- The client issues a GraphQL HTTP request which instructs the GraphQL Handler
C to generate the necessary pre-signed POST data. - Once the client receives the pre-signed POST data, in a new POST HTTP request, the data, and the actual file are uploaded to the S3 bucket
G1 . - Finally, another GraphQL request is issued, which instructs the GraphQL Handler
C to store the file meta data. The data is stored both in Amazon DynamoDBE and Amazon OpenSearch ServiceF .
FAQ
Who Can Upload Files?
Only users with proper permissions can perform file uploads. Both authentication and authorization are performed in steps one and three, on the GraphQL Handler Is There a Way to Define a Maximum File Upload Size?
Yes, by going into the File Manager’s general settings section, and manually entering the appropriate values.
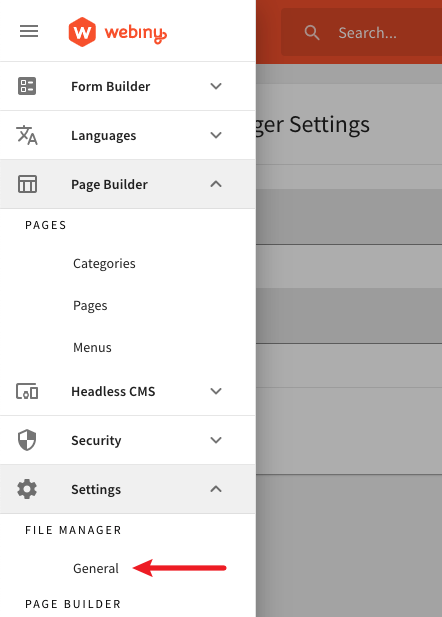 File Manager Settings
File Manager Settings