Webiny Overview > Applications
Headless CMS
A scalable GraphQL-based headless CMS built on top of serverless infrastructure.
- Features, capabilities and, common use-cases of Webiny’s Headless CMS.
 Webiny CMS - Serverless Headless CMS
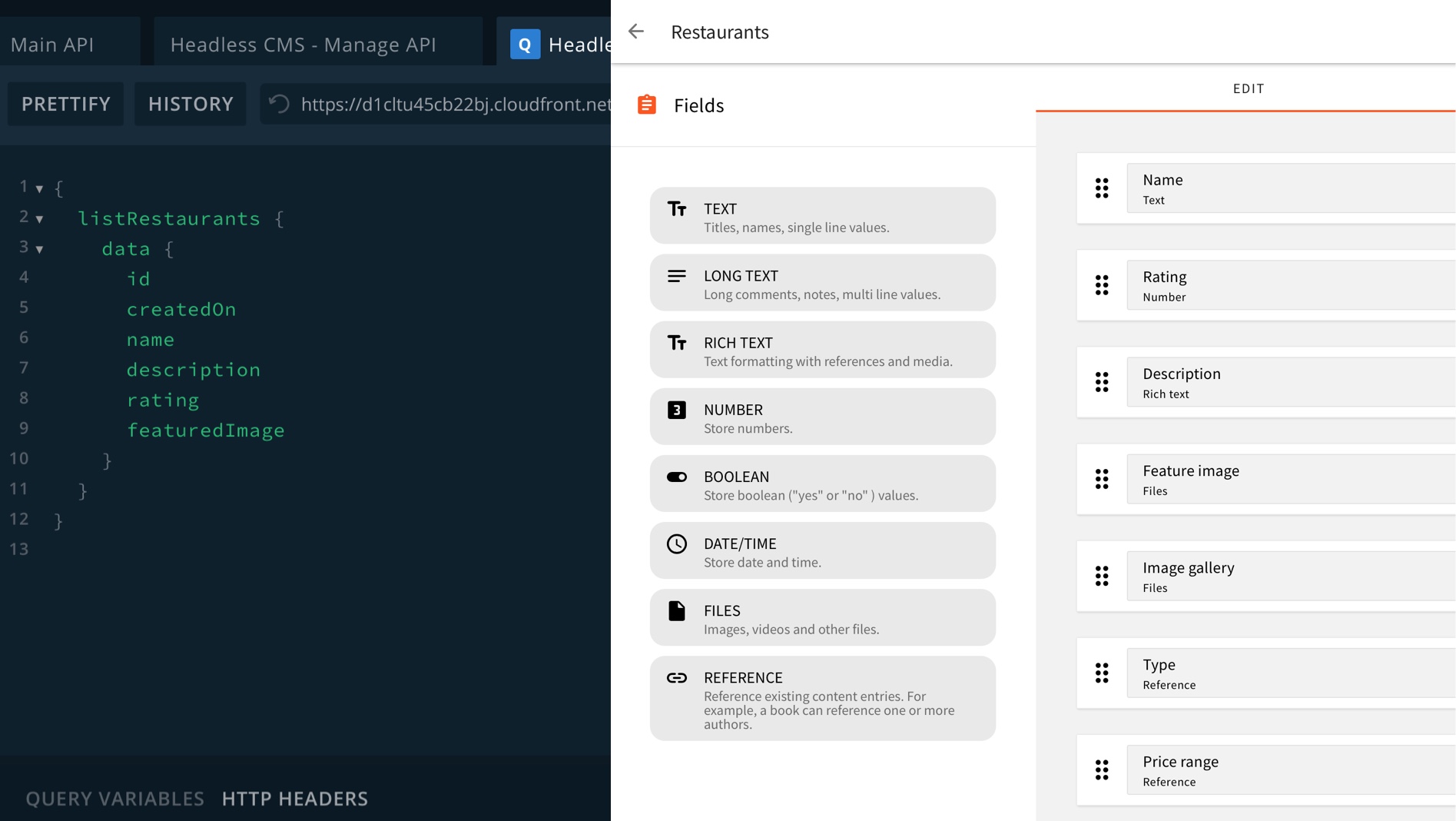
Webiny CMS - Serverless Headless CMSAt the core of Webiny Headless CMS are three scalable GraphQL APIs. The read, manage, and preview.
When it comes to defining content models, there are also three different approaches at your disposal:
- No-code approach using the UI editor
- API approach using the
manageAPI - Code approach by defining the models directly through code You can pick a single approach or use a combination, whichever works better for your use case.
Use the Headless CMS to power backends for business applications, mobile apps and to manage data for a website, like blogs or eCommerce stores.
Features
Headless CMS packs many features that make it a powerful tool to create a new API quickly. Let’s explore some of its main features.
Content Modeling
Under the term “content model” we refer to an entity that consists of one or more attributes. A typical content model would be a blog post. That content model would contain attributes such as title, slug, featured image, tags, category, and a body.
Each attribute can be of a different type. The included types are:
- Input
- a single-line text input or a multi-entry input
- can also be a list of predefined values the user can select
- Number
- A integer or a float
- Text
- Multi-line text
- Doesn’t support text formatting
- Rich text
- A multi-line rich text field that supports text formatting and inline images
- Boolean
- True or false toggle
- File
- Used for inserting a single file, multiple files, a single image or an image gallery
- Reference
- Referencing another content model
- Supports both single entries and multiple select
- Object
- Nested object field
- Inside this field you can place multiple other fields such as text, file and others
- You can nest objects to as many depth levels as you need
- Dynamic zone
- A dynamic zone is a field that can contain multiple other fields
- The difference between a dynamic zone and an object is that a dynamic zone allows you to select which fields you want to use
- This is useful when you have a content model that has a lot of fields, but you only want to use a few of them in a particular entry
- You can also nest dynamic zones to as many depth levels as you need
- See Dynamic Zone in action: https://www.youtube.com/watch?v=8Z3Z3Y5Q5Zo

Besides the default built-in attributes, you can expand Webiny with custom plugins that introduce new fields.
Checkout the tutorial on Creating a Webiny Headless CMS custom field plugin.
Validators
On each of the attributes, you can attach one or more validators. They define which fields are required and what values, or patterns, of values a field can take. There is also the ability to attach a unique field validator to specific fields.
GraphQL API endpoints
The Headless CMS has 3 APIs which expand dynamically every time you create a new content model. Therefore, depending on what you want to do, you will use a different endpoint:
ManageAPI endpoint- This is the primary endpoint; it allows you to create, delete, publish, unpublish and many other read and write operations.
ReadAPI endpoint- Only has queries to read data. It can only read data that is published.
PreviewAPI endpoint- Similarly to the Read API, with the exception that it returns the latest version of the content, regardless if the latest version is published or not.
You can explore the queries and mutations available under each of the APIs inside the Admin Panel by accessing the API Playground from the main menu.
Security
From the security module in the main menu, you can control the access levels for both user groups as well as API tokens.
For the Headless CMS, the security implementation allows you to define access to the content. You can limit access to a particular content model or a content model group. Within that, you can control what operations are allowed. Is it ready-only access, or can the content be manipulated. And then which content is in the scope of that operation, is it only the content the user previously created himself, or all the content. This fine-grain control allows you to fully tweak the access levels to meet your business requirements.
When it comes to API tokens, you can also limit them to a particular endpoint alongside all the above-mentioned options.
Multi-Language
All apps inside Webiny are multi-language. The multi-language implementation is done in a way that each language is fully independent in terms of content and content models. This approach is the most flexible in terms of what you can do with it as each language can have a completely different content and structure. The tradeoff is that in some cases there will be some manual coding required say if you are reading an article in German and you want to switch to the same article in English. This switching logic and linking the German and English entry would be up to you to implement.
Scale and Performance
There are 2 main operations that you can do on the Headless CMS which will define your scale factors. First is the write operation on the Manage API. These operations trigger a lambda function which then writes a record into DynamoDB. As you can imagine, this flow can easily handle thousands of requests per second. The data from DynamoDB is then written in batches into Elasticsearch service via a DynamoDB stream.
The second operation is the read operation, which comes when you interact with the Read or the Preview API. In this case, it’s a Lambda function that interacts with Elasticsearch, there is no DynamoDB.
The only time when Webiny uses DynamoDB to fetch items from the database is when you are requesting a particular item via the primary key.
The data inside the Elasticsearch service is stored so it can be quickly retrieved, no matter if there are filters and sorters applied. This includes also all the linked references. The scale factor here depends on the size of your Elasticsearch instance. This is the only “non-serverless” component Webiny uses so you need to think about sizing in advance.
For an in-depth performance benchmark checkout the performance benchmark.
When to Consider Webiny’s Headless CMS
Here are some key differentiators for when you should consider using Webiny’s Headless CMS:
- Data ownership
- In both the open-source and the enterprise edition, Webiny is self-hosted. So if you need a highly scalable headless CMS solution, but don’t want to spend a lot of resources on managing and scaling infrastructure, Webiny is a great option.
- Customizability
- Headless CMS can be fully tailor-made to your requirements. Being open-source you have full control over the code which you can modify to your needs.
- Cost
- All of the infrastructure components Webiny uses, besides Elasticsearch, have consumption-based pricing, they scale automatically and require zero maintenance. Serverless in practice lowers infrastructure costs by 60-80% and maintenance costs by 60%.
- Scalability
- With Webiny there is almost no need to reconfigure and redesign your infrastructure as your demand grows or shrinks. It’s a solution that you can use to start serving 100 users a day and the next day scale to handle over 10 million users a day or more.